


来源: 科小二 2025-06-10 10:44:51
当我们使用像ChatGPT这样的对话系统时,常常会被它流畅的回答所惊艳,直到发现它在简单数学题上犯错时才意识到其局限性。这种对比揭示了大型语言模型的一个关键特性——它们擅长模仿语言模式,但在理解和推理方面存在不足。
现代大型语言模型是基于对海量文本数据的学习来构建的。通过分析这些数据中的词语关系,模型学会了如何根据上下文生成合理的答案。例如,当被问到“地球为什么是圆的?”时,模型给出的答案并不是因为它真正理解了天体物理学,而是因为它学习到了最有可能出现在这类问题之后的文字组合。这种方法在处理日常对话和信息查询时效果显著,但在面对需要多步逻辑推理的任务时,就显得力不从心。

为了让AI获得真正的思维能力,研究者们开发出了"思维链"(Chain-of-Thought)技术。CoT 的核心在于引导模型在回答问题时输出中间推理步骤,而不是直接给出最终答案。这种方法通过提示工程让模型生成具有逻辑连贯性的文本序列,使其输出看起来像是在“一步步推导”,从而提升处理复杂任务的能力和结果的可解释性。
举个例子,想象你在教小朋友做加法:
● 错误教法:"3+5等于8"
● 正确教法:"我们先数3个苹果🍎🍎🍎,再数5个苹果🍎🍎🍎🍎🍎,现在一起数:1,2,3...8!总共有8个苹果"

"思维链"技术就是让AI采用第二种方式。具体实现方法很巧妙:
1. 在训练时给AI看大量带有详细步骤的例子
2. AI学会在回答时自动生成中间推导过程
3. 每个中间步骤都会影响下一个步骤的生成
这就像让AI养成"自言自语"的习惯。实验证明,仅仅是要求AI"让我们一步步思考",就能显著提高其回答复杂问题的准确率。

思维链技术的训练过程同样独具匠心。研究者发现,只需在提示信息中加入一些带有中间推理步骤的示例,就能引导大模型在回答问题时逐步展开思路,而不是直接输出答案。
通过这种方式,人工智能学会了在给出最终答案前先构建中间推论,就像数学家证明定理时需要展示每一步的推导过程一样。实验数据显示,仅仅是要求AI"让我们一步步思考",就能使它在某些数学问题上的准确率提高一倍以上。
为了进一步提升模型的推理能力,研究人员引入了强化学习的方法。他们通过设定评分机制,对模型输出的推理过程进行评估,并以此为依据优化模型的行为,类似于教师对学生作业进行批改和反馈,从而帮助 AI 更好地掌握复杂任务的解决策略。
以教AI解一元二次方程为例:当遇到题目"x²-5x+6=0"时,AI会尝试三种解法——因式分解法、求根公式法和图像法。专家系统就像严格的老师一样检查每个解法:因式分解得到(x-2)(x-3)=0完全正确且步骤简洁(奖励+10分);求根公式虽然结果正确但计算复杂(奖励+5分);图像法耗时且不够精确(奖励0分)。通过这种评分机制,AI明白因式分解是最优解。
接下来是关键的学习过程:AI会运用反向传播算法(可以理解为"复盘总结"),根据获得的奖励分数调整内部参数。就像学生会重点复习得高分的解题技巧一样,AI会加强因式分解相关的神经连接权重。经过多次这样的训练循环后,当AI再遇到类似方程时,就会优先选择因式分解法这个最优方案。整个过程实现了从"尝试多种方法"到"掌握最佳方案"的智能进化。
经过数百万次这样的训练后,人工智能就能建立起稳定的逻辑思维能力。
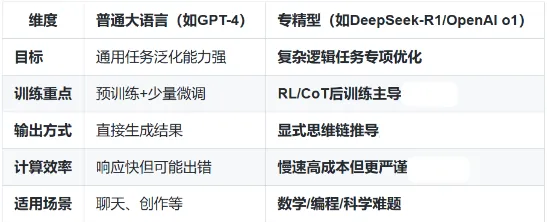
通用大语言模型(如基于Transformer架构的那些)主要用于处理广泛的主题,并依赖于从互联网收集的大规模文本数据进行训练。相比之下,专门设计用于特定领域推理的专业推理模型不仅采用了类似的Transformer架构作为基础,还集成了额外的功能模块,例如符号计算引擎和外部知识验证接口,以增强其在特定领域的推理能力。此外,在训练数据的选择上,通用模型侧重于多样化的网络文本资料,而专业推理模型则包含了大量数理题目及其详细解题步骤。这种差异意味着,在面对复杂的数学或逻辑问题时,专业推理模型能够提供更高的准确性和可靠性。
尽管这些技术进步令人振奋,我们必须清醒认识到当前人工智能的局限性所在。这些系统仍然依赖于统计模式而非真正的理解,无法自主发现新的解题方法,在处理开放性问题时也常常力不从心。最新的研究方向正试图融合神经网络的模式识别能力与传统符号系统的逻辑推理机制,并探索构建能够模拟现实规律的“世界模型”,以期突破当前的技术瓶颈。
当我们观察这些会"思考"的人工智能系统时,实际上也在重新审视人类智能的本质特征。每一次技术进步都在提醒我们:
真正的智能不仅需要庞大的知识储备,更离不开严谨的逻辑架构和深刻的洞察力。这或许正是即使是最先进的 AI 系统,也仍然难以达到人类思维所具有的深度与广度的原因。


























